Want to hear more from us?
SubscribeChatGPT vs Situational Judgement Tests: how it performs vs a human (Clone) (Clone)
Monday 25th September
-

-

-

-

- Subscribe

If the researchers at OpenAI thought ChatGPT could reason better than a human, and our own research showed that ChatGPT-4 performed better than 98.8% of all candidates on a Verbal Reasoning Test, then the logical next question might be… “How is its judgement?”
For months, there has been talk in the recruitment community about whether a candidate could really use ChatGPT to complete a Situational Judgement Test (SJT) with little to no specialist training. Some other researchers have already completed research in this area, and this is a useful foundation. But we wanted to dig a bit deeper and understand how easy it is and what the different approaches to prompting might reveal. As well as the difference in performance between GPT-3.5 and GPT-4.
So, for the second instalment of our ‘ChatGPT vs psychometric assessments’ series, our Senior Data Scientist, working alongside two UCL postgraduates, set out to answer these questions:
- Could ChatGPT outperform the average candidate on a Situational Judgement Test?
- How did ChatGPT's performance vary across the free version (GPT-3.5) and the paid, £15 / $20 a month, version (GPT-4)?
- How simple or complex would the prompts (or inputs) need to be for ChatGPT to get the correct answer?
- What other factors might impact ChatGPT’s performance?
Throughout this research piece, we’ll outline our research methodology as well as our findings. But in case you just wanted the headlines…
TL;DR
- Both GPT-3.5 and GPT-4 can complete SJTs, with GPT-3.5 (free) getting 50-60% of SJT questions correct, and GPT-4 (£15 a month) getting 65-75% of SJT questions correct
- GPT-4 was consistently found to score among the 70th percentile or higher when compared against human performance on an SJT, even in cases where the question required it to rank its answers (if you’re not familiar, we explain what this means, and why it’s important, below)
- GPT-4 is –– unsurprisingly –– able to handle more complex reasoning than its predecessor and is much better at following its own advice
- ChatGPT can be configured to be more creative allowing for more uniquely human responses –– in some cases, this improves its performance, but it does make its ability to score highly on the assessment much more unpredictable
- The consequences? Recruiters may see an increase in the number of candidates passing SJTs but a reduction in the quality of candidates at the interview stage (because their scores don't match their capability)
- Given the paid version of ChatGPT outperforms its free predecessor, it has the potential to create a bigger gap between candidates with the financial means to pay for it and those who don’t
Now into the details…

What is a Situational Judgement Test and when would you use it?
Situational Judgement Tests (SJTs, for short) are a type of psychological assessment used to measure how candidates approach and resolve common situations they might come across at work.
They’re often one part of a psychometric assessment, alongside assessments for Aptitude and Personality, and typically assess things like a person’s decision-making skills, organisation and planning, resilience, and communication skills.
The tests work by presenting hypothetical, job-related situations, and asking the test-taker to choose the most appropriate action from a set of multiple choice questions. You can see an example of what one might look like here.
The exact nature of the scoring and how points are allocated varies based on the test provider but there is always a hierarchy –– some answers will get you more points as they are ‘more correct’ and some will give you fewer points because they are ‘less correct’.
In some scenarios, candidates might be asked to rank the multiple choice options from ‘best to worst’ or ‘most likely to least likely’, or they might just be asked to select ‘the best’ vs. ‘the worst’ option. Either way, a test provider will always be looking for –– and awarding points –– based on a ‘desirable’ answer.
You can think of an SJT a bit like a pseudo-interview: the assessment is trying to understand how a candidate will behave in the role by asking them how they’d react in certain situations.
The downsides of this approach?
- Just like with training for an interview, candidates can be coached on SJTs. This is proven to improve their scores by up to 25%, blurring your view of their true behaviours.
- Likewise, academics have raised concerns about whether SJTs actually measure the behaviours that they claim to measure — or if they mix up those behaviours with knowledge and personality. (Michael A. McDaniel, Sheila K. List and Sven Kepes - 2016; M. Catano, Anne Brochu, Cheryl D. Lamerson - 2012; Anna Koczwara, Fiona Patterson, Lara Zibarras, Maire Kerrin, Bill Irish, Martin Wilkinson - 2012). Again, this risks blurring your view of what candidates are actually like.
And now, with Generative AI models like ChatGPT able to easily interpret test questions and generate optimal answers quickly, whether or not a question-based SJT can truly assess how someone will behave at work hangs in the balance.
This leads us back to the question at hand –– can generative AI tools like ChatGPT really be used by candidates to complete Situational Judgement Tests, with little or no specialist training?
Here’s how we went about finding out.

Our research methodology
Arctic Shores does not offer an SJT. We wanted to conduct this research to help the talent acquisition industry make informed decisions about the best ways to assess candidates' true potential to succeed in a role in the age of Generative AI. And as part of that, we wanted to identify whether an SJT was a robust option to do that.
For that reason, our research squad tested ChatGPT against a series of practice tests readily available for any candidate to buy online, using information from the test providers themselves to determine the percentile ranking of ChatGPT’s scores in comparison to others who’ve taken the test.
Explaining the questions to ChatGPT
To see if ChatGPT could complete an SJT, we first needed to explain the questions to it in the same way that a candidate would. There are many different ways of framing information for ChatGPT, commonly known as ‘prompting’.
After a lot of research, we settled on five distinct GPT prompting styles to investigate. These are some of the most accessible styles, which any candidate can find online by Googling “best prompting strategies for ChatGPT”. This is what the prompts and examples looked like:
- Base Prompting: The most basic approach, which involves simply giving ChatGPT the same basic instructions a candidate receives within the assessment
- Chain-of-Thought Prompting: The next level up from Base Prompting gives ChatGPT an example of a correctly answered question within the prompt (using an example practice question from a testing practice website)
- Generative Knowledge Prompting: As an alternative approach, this prompting style asks ChatGPT to explain the methodology it will use before it answers the question. This gives the candidate the chance to train ChatGPT briefly.
- Persona / Role-based Prompting: ChatGPT has the capability to take on a persona so it can be instructed to assume a role, such as “You are an experienced corporate analyst at a large financial services organisation” –– this prompting style encourages ChatGPT to think about its role as it crafts its answers.
- Vocalise and Reflect Prompting: This style involves asking ChatGPT to create a response, critique that response, and then iterate on the original draft based on its own critique –– a self-learning type of approach.
You can find examples of the prompts in our downloadable pdf, which also covers: a drill down on rank order questions, plus a bonus experiment on whether simple prompting changes can help craft more human responses.
Testing the most common GPT models
We decided to test both the free and paid versions of ChatGPT to determine whether or not candidates with the financial means to pay for GPT-4 –– which sits behind a paywall at £15 a month –– would be at a significant advantage vs their peers using the free version, GPT-3.5. Here’s a summary of the differences between the two versions:

To time or not to time
It’s worth noting that some SJTs operate within time limits –– in the early stage of our research, we observed that the speed at which we were able to craft a prompt and get a response from ChatGPT meant that timing our tests wasn't necessary; because ChatGPT would always be able to respond almost as fast a candidate.
This was helped by basic smartphone features. For example, ChatGPT's iPhone App has a text scanning feature which allows you to scan a question on your phone, ask for a response, and enter that answer on your computer in a few seconds.
The interesting point to note is that using a phone to scan the text of the question was as fast as reading the items. To the point where, with only a bit of practice, it’s easy to go from input to final answer as fast as human candidates. Especially considering that this was done on GPT-3.5, which got the correct answer. We therefore hypothesise that using GPT-4 would be even more effective, given its enhanced reasoning ability.

The results –– can ChatGPT be used to complete an SJT?
In short, yes it can.
GPT-3.5 got an average of 50-60% of SJT questions correct and the premium version –– GPT-4 –– got an even more impressive 65-75% of SJT questions correct, putting it into the 70th percentile in comparison to previous test-takers' scores.
While the differences between prompting styles might seem subtle, there’s a big disparity when we look at the different versions. GPT-4 isn’t just better overall — it reveals some unexpected, specific strengths over its forebear.
The headline: GPT-4 excels at complex reasoning, while GPT-3.5 prefers to keep things simple.
Next, we’ll explore the data underpinning this claim… and why it’s so important.
GPT-4 excels at completing rank order questions
If you remember, some SJTs require candidates to sift through multiple answers, ranking them in order of effectiveness. In these scoring systems, when the candidate ranks an answer correctly, they’re given a whole point. But sometimes there's a bit of wiggle room — like when an answer is almost right. Here the candidate is given a partial score, like 0.5.
If that sounds too much like some shape-shifting jigsaw puzzle, then you can also visualise it this way. (We wanted to share an example of a question here to illustrate what we mean, but we're keen not to call out any provider specifically. So, for the sake of illustration, we've made up a slightly offbeat example).
Based on the scenario described, please review the following responses and suggest which one you believe to be the response to the situation you would be ‘most likely to make’ and ‘least likely to make’.
“You're a recruiter for a highly prestigious intergalactic corporation. You've just discovered that the best candidate for your new Galactic Sales Manager role is an alien named Targ. Her references are impeccable, but come from galaxies you've never heard of; and you're concerned about how she'll integrate into the Earth office environment. Also, she eats stationery as snacks.”
Please rank the following actions from 1 (most effective) to 5 (least effective):
- Conduct a surprise snack-time visit to see if Targ prefers paper clips over staplers. This way, you can stock up on her favourites and minimise office supply losses.
- Organise an 'Earth Culture' training day where all employees, including Targ, can share and learn about each other's galactic backgrounds.
- Hire Targ immediately without hesitation because who cares about a few missing pens when you've got the best talent in the galaxy?
- Introduce a 'Bring Your Own Stationery' policy and discreetly inform the team so everyone is prepared.
- Decline Targ's application on the basis that no amount of talent is worth the loss of the office's precious limited-edition Saturn-shaped erasers.

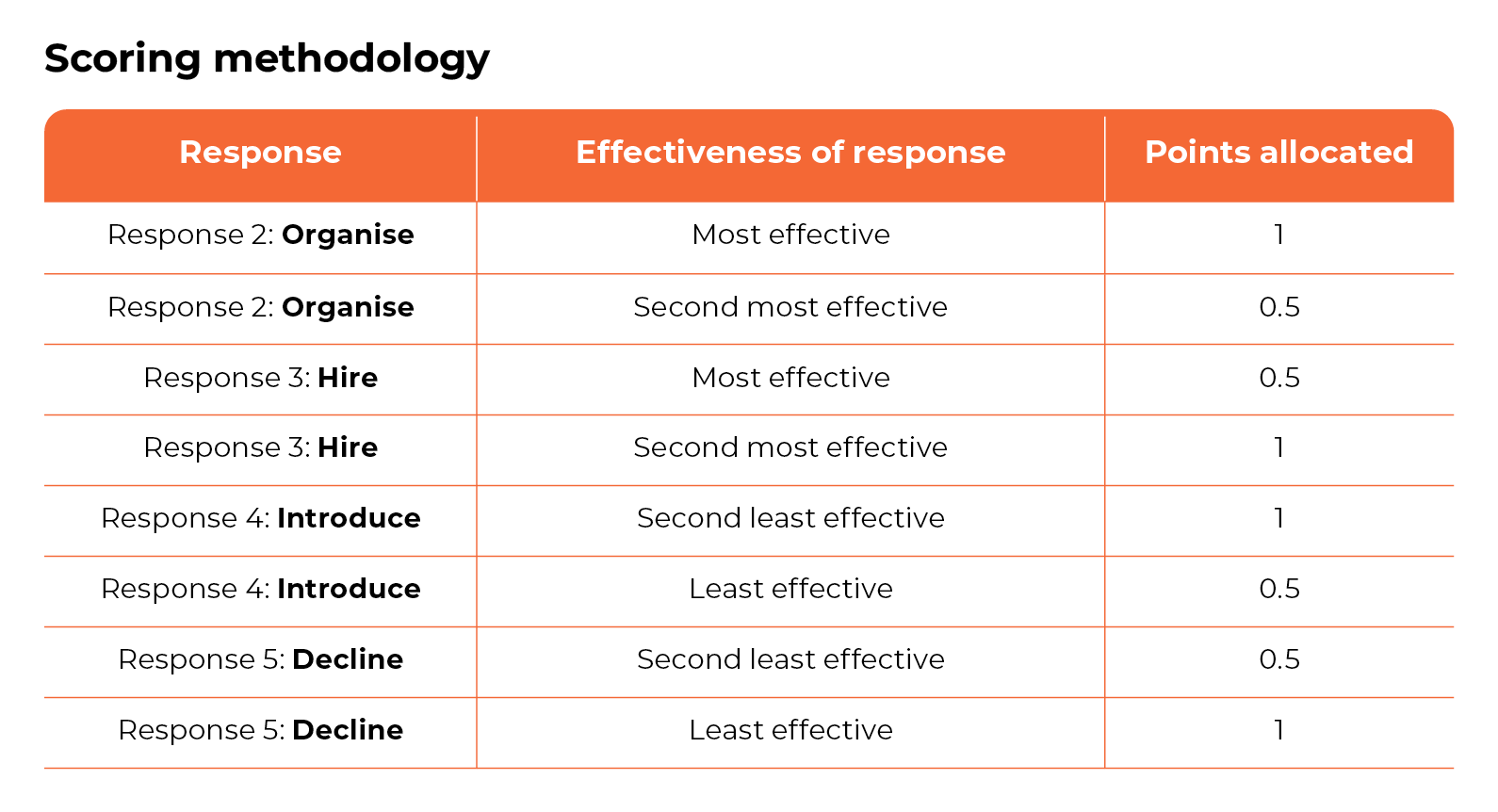
Why is this important? There have been some reports from SJT assessment providers that ChatGPT can only operate in a binary context and doesn’t perform well when you ask it to evaluate the options in a more complex way. For example, by ranking the effectiveness of each answer.
However, despite some small differences between the models, we found that this wasn’t the case.
Both versions of ChatGPT performed well when selecting the ‘most effective’ answer. And even if GPT-4 didn’t pick the ‘most effective’ answer, it picked the next best one in most cases. Therefore, it was able to consistently achieve either a full or a partial score.
GPT-4 also performed well when identifying ‘the least effective’ solution to a scenario.
Conversely, while GPT-3.5 was generally pretty good at predicting which options were ‘the most effective’, it performed less well than its paid successor in identifying the ‘least effective’ solution. This could be a result of a weakness in its counterfactual reasoning.
GPT-3.5’s inability to spot the ‘least effective’ solution was especially true when it was given the default assessment instructions or using a Generative Knowledge prompting style.
This leads us to conclude that while ChatGPT does perform ‘better’ if there is a binary right or wrong answer, GPT-4 still performs very well in a more nuanced context –– even if being asked to give a solution to a problem with a ‘rank order’.
The difference in capability between models? GPT-4 is better at applying its own logic
Having uncovered these differences between the models, we wanted to see if GPT-3.5 understood less about the SJT and how to approach it vs its counterpart. And if that was driving the difference in performance. To find out, we asked ChatGPT how it would approach taking a Situational Judgement Test.
Both GPT-3.5 and GPT-4 gave good, logical descriptions about how to approach an SJT –– which wasn’t particularly surprising.
This told us that GPT-3.5 didn’t score as highly because it had worse knowledge of SJTs and didn’t know what to do. Rather, it simply struggled to apply that logic to its responses.


If ChatGPT can outperform the average candidate on an SJT, what does that mean for TA teams?
This research leads us to conclude that candidates can use ChatGPT to complete traditional, question-based Situational Judgement Tests with little-to-no specialist training.
It shows that those candidates who do so will outperform their peers, and those with the financial means to pay for GPT-4 will outperform their peers even more so.
It also disproves the myth that ChatGPT isn’t effective at completing assessments with a rank order scoring system.
So what are the repercussions for recruitment?
- An increase in pass rates but a drop in candidate quality: Given how easy it now is for a candidate to use ChatGPT to complete an SJT and achieve a score that puts it in the 70th percentile of human test takers, an SJT could quickly cease to serve as a useful tool for Sifting. This could result in more candidates making it to the interview stage whose ability doesn’t appear to match up to their score, wasting recruiter time, and losing hiring managers' faith in the process. TA teams may need to consider raising the pass threshold, perhaps excluding a high percentage of quality candidates in the process.
- Setting back social mobility efforts: The difference in results on GPT-3 and GPT-4 was significant. But with GPT-4 sitting behind a paywall, candidates with the financial means to pay for it will suddenly have an advantage over those who don’t — potentially setting back all of the hard work TA teams have done over the past few years to try and increase diversity and social mobility.
- Re-evaluating the usefulness of the traditional SJT: If ChatGPT can make judgement calls as nuanced as a human, does an SJT really tell us about a candidate’s ability to succeed in the modern workplace? After all, SJTs have been subject to criticism for years for their construct validity and not actually measuring what they intend to — as they end up being more of a reasoning test, as per the research cited above. In light of these findings, we believe that TA teams should re-evaluate what purpose Situational Judgement Tests are serving in their recruitment process, and whether they really help to understand things like a person’s resilience, decision-making and communication skills.

TA leaders have three options to tackle this challenge
- Detect - Continue using traditional, text-based Situational Judgement Tests, but try to use additional tools to detect if candidates are using Generative AI to complete them. Given that the detection-proof method of turning up the Temperature on ChatGPT often results in worse performance, this could still seem like a viable option.
But the main challenge with this approach is that no ChatGPT detection models have been shown to work effectively as of today, with some even reporting that 2 in 10 times these detection methods produce a false positive, meaning you risk falsely accusing candidates of cheating, potentially harming your employer brand.
It’s also worth noting that given how quickly the underlying language models change and improve, there’s a chance these detection methods could quickly become out of date. - Deter - Attempt to prevent candidates by using (already unpopular) methods like video proctoring, which have been around for several years but received strong pushback from candidates. These methods are also likely to increase candidate anxiety, shrinking your talent pool further (Hausdorf, LeBlanc, Chawla 2003).
Simpler methods like preventing multiple tabs from being open at a time or preventing copy and paste from within a browser are options, but even these can be easily bypassed with a phone.
For example, candidates can use the ChatGPT iPhone app to scan an image, get a response, and input the suggested answer into a computer in just a few seconds. - Design - Look for a different way to assess how a candidate would really behave at work and in a way that cannot be completed by ChatGPT. The starting point is to choose an assessment type that isn’t based on language, and so can’t easily be completed by large language AI models like ChatGPT. Of course, we have our own preference on this one; but based on our research, interactive, task-based assessments currently prove much more robust and less susceptible to completion by ChatGPT because they create scores based on actions, not language. They also give you the added benefit of being able to assess Personality and Cognitive Ability all in one.
If you’re looking to measure communication skills, you might also consider a more practical way to assess those skills, like using a video screening platform.
Where to go from here
Given the pace at which these models are moving, what is true today may not remain true for very long. So while you think about adapting the design of your selection process, it’s also important to stay up-to-date with the latest research.
We’re continuing to explore the impact of ChatGPT across the wider assessment industry. You can view our summary of ChatGPT vs. Aptitude Testing here or sign up for our newsletter to be notified when our next piece of research drops.
The focus? Our researchers have been exploring whether ChatGPT has a default Personality type and how easy it is to adapt it to complete –– and score desirably –– on a traditional, question-based Personality Assessment.
Subscribe below and be the first to know which assessment format you should choose to future-proof your selection process.